REST and GraphQL are two ways to send data over HTTP. The REST-based approach is the traditional way of doing so and has gained a very high adoption rate in many application stacks in the last years.
GraphQL is often presented as a revolutionary new way to think about APIs. Indeed GraphQL is able to overcome major shortcomings of REST. In this article we will talk about differences between both technologies and discuss how GraphQL can help you to build highly flexible APIs for your applications. Let’s get started.
The Rest architecture
REST is an architectural style that came out of Roy Fielding’s PhD thesis in 2000, is an API design architecture used to implement web services. REST-compliant web services allow the requesting systems to access and manipulate textual representations of web resources by using a uniform and predefined set of stateless operations. When HTTP is used, the most common operations available are GET, POST, PUT, and DELETE.
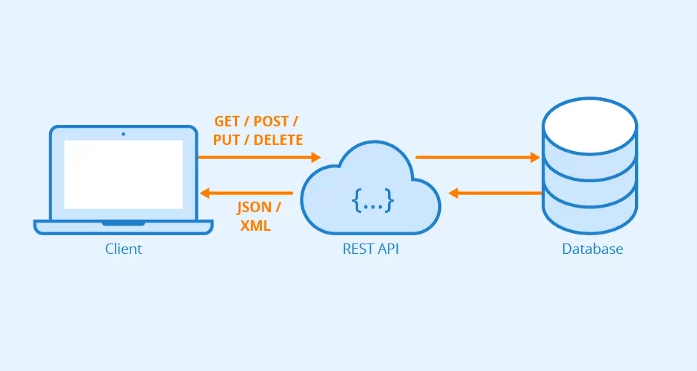
The core concept of REST is that everything is a resource. While REST was a great solution when it was first proposed, there are some pretty significant issues that the architecture suffers from right now. Let’s explore some of the most significant limitations.
Limitations of REST
Most web and mobile applications developed today require large sets of data that typically combine related resources. The problem is that accessing all of that data to get everything you need using a REST-based API requires multiple round trips. For example, if you wanted to retrieve data from two different endpoints, you’d have to send two separate requests to the REST API.
Another common problem developers face with REST is over- and under-fetching. This is because clients can only request data by hitting endpoints that return fixed data structures. Due to this, they aren’t able to get exactly what they need and run into either an over-fetch or an under-fetch scenario.
- Over-fetching is when the client downloads more information than what the application actually needs.
- Under-fetching is when the endpoint doesn’t provide all of the required information so the client has to make multiple requests to get everything the application needs.
For example, let’s say you’re working on a screen for an app that needs to display a list of users with their names and birthdays. The app would hit the /members endpoint and, in turn, receive a JSON data structure with the user data. However, the data structure would contain more information about the users than what’s required by the app. For example, it might return the user’s name, birthday, email address, and phone number.
What is GraphQL?
GraphQL is a language for defining data schemas, queries and updates developed by Facebook in 2012 and open sourced in 2015. The key idea behind GraphQL is that instead of implementing various resource endpoints for fetching and updating data, you define the overall schema of the data available, along with relationships and mutations (updates) that are possible. It means that GraphQL is much more flexible than Rest.
You can tailor the request (query) to your exact needs by using the GraphQL query language and describing what you would like to get as an answer. You can combine different entities in one query and you are able to specify which attributes should be included in the response on every level e.g.:

Why use GraphQL?
The key advantage of GraphQL is that once the data schema and resolvers have been defined:
- Clients can fetch the exact data they need, reducing the network bandwidth required (caching can make this tricky–more on this later).
- At frontend you can write your code with much less dependency with the backend, since the backend pretty much exposes all the data that is possible. This allows front end team to operate faster.
- Since the schema is typed, it is possible to generate type-safe clients, reducing type errors.
Every time you modify your application’s UI, there’s a pretty good chance that your data requirements will also change i.e. you’ll either need to fetch more data or less data than before. GraphQL makes rapid product iterations on the front-end possible as it allows developers to make changes on the client-side without messing around with the server.
GraphQL allows us to have fine-grained insights about the data that’s requested on the backend. As each client specifies exactly what information it’s interested in, it is possible to gain a deep understanding of how the available data is being used. This can for example help in evolving an API and deprecating specific fields that are not requested by any clients any more.
With GraphQL, we can also do low-level performance monitoring of the requests that are processed by our server. GraphQL uses the concept of resolver functions to collect the data that’s requested by a client. Instrumenting and measuring performance of these resolvers provides crucial insights about bottlenecks in our system.
Conclusion
Both REST and GraphQL are prominent ways to design how an API will function and how applications will access data from it. While REST had significantly simplified the work of developers with its standardized approach, it does have a few drawbacks. GraphQL, with its queries, schemas, and resolvers offer more flexibility, moreover, GraphQL can offer better performance.
REST still holds on it own though, and you can use both REST and GraphQL in a project. Carefully analyze your application, data, and performance requirements, so that you can choose appropriately.